No Code Metadata
Summary of changes
As part of the No Code Metadata Modeling initiative, we've made radical changes to the DataHub stack.
Specifically, we've
- Decoupled the persistence layer from Java + Rest.li specific concepts
- Consolidated the per-entity Rest.li resources into a single general-purpose Entity Resource
- Consolidated the per-entity Graph Index Writers + Readers into a single general-purpose Neo4J DAO
- Consolidated the per-entity Search Index Writers + Readers into a single general-purpose ES DAO.
- Developed mechanisms for declaring search indexing configurations + foreign key relationships as annotations on PDL models themselves.
- Introduced a special "Browse Paths" aspect that allows the browse configuration to be pushed into DataHub, as opposed to computed in a blackbox lambda sitting within DataHub
- Introduced special "Key" aspects for conveniently representing the information that identifies a DataHub entities via a normal struct.
- Removed the need for hand-written Elastic
settings.jsonandmappings.json. (Now generated at runtime) - Removed the need for the Elastic Set Up container (indexes are not registered at runtime)
- Simplified the number of models that need to be maintained for each DataHub entity. We removed the need for
- Relationship Models
- Entity Models
- Urn models + the associated Java container classes
- 'Value' models, those which are returned by the Rest.li resource
In doing so, dramatically reducing the level of effort required to add or extend an existing entity.
For more on the design considerations, see the Design section below.
Engineering Spec
This section will provide a more in-depth overview of the design considerations that were at play when working on the No Code initiative.
Use Cases
Who needs what & why?
| As a | I want to | because |
|---|---|---|
| DataHub Operator | Add new entities | The default domain model does not match my business needs |
| DataHub Operator | Extend existing entities | The default domain model does not match my business needs |
What we heard from folks in the community is that adding new entities + aspects is just too difficult.
They'd be happy if this process was streamlined and simple. Extra happy if there was no chance of merge conflicts in the future. (no fork necessary)
Goals
Primary Goal
Reduce the friction of adding new entities, aspects, and relationships.
Secondary Goal
Achieve the primary goal in a way that does not require a fork.
Requirements
Must-Haves
- Mechanisms for adding a browsable, searchable, linkable GMS entity by defining one or more PDL models
- GMS Endpoint for fetching entity
- GMS Endpoint for fetching entity relationships
- GMS Endpoint for searching entity
- GMS Endpoint for browsing entity
- Mechanisms for extending a **browsable, searchable, linkable GMS **entity by defining one or more PDL models
- GMS Endpoint for fetching entity
- GMS Endpoint for fetching entity relationships
- GMS Endpoint for searching entity
- GMS Endpoint for browsing entity
- Mechanisms + conventions for introducing a new relationship between 2 GMS entities without writing code
- Clear documentation describing how to perform actions in #1, #2, and #3 above published on datahubproject.io
Nice-to-haves
- Mechanisms for automatically generating a working GraphQL API using the entity PDL models
- Ability to add / extend GMS entities without a fork.
- e.g. Register new entity / extensions at runtime. (Unlikely due to code generation)
- or, configure new entities at deploy time
What Success Looks Like
- Adding a new browsable, searchable entity to GMS (not DataHub UI / frontend) takes 1 dev < 15 minutes.
- Extending an existing browsable, searchable entity in GMS takes 1 dev < 15 minutes
- Adding a new relationship among 2 GMS entities takes 1 dev < 15 minutes
- [Bonus] Implementing the
datahub-frontendGraphQL API for a new / extended entity takes < 10 minutes
Design
State of the World
Modeling
Currently, there are various models in GMS:
- Urn - Structs composing primary keys
- [Root][Snapshots](https://github.com/datahub-project/datahub/blob/master/metadata-models/src/main/pegasus/com/linkedin/metadata/snapshot/Snapshot.pdl) - Container of aspects
- Aspects - Optional container of fields
- Values, Keys - Model returned by GMS Rest.li API (public facing)
- Entities - Records with fields derived from the URN. Used only in graph / relationships
- Relationships - Edges between 2 entities with optional edge properties
- Search Documents - Flat documents for indexing within Elastic index
- And corresponding index mappings.json, settings.json
Various components of GMS depend on / make assumptions about these model types:
- IndexBuilders depend on Documents
- GraphBuilders depend on Snapshots
- RelationshipBuilders depend on Aspects
- Mae Processor depend on Snapshots, Documents, Relationships
- Mce Processor depend on Snapshots, Urns
- Rest.li Resources on Documents, Snapshots, Aspects, Values, Urns
- Graph Reader Dao (BaseQueryDao) depends on Relationships, Entity
- Graph Writer Dao (BaseGraphWriterDAO) depends on Relationships, Entity
- Local Dao Depends on aspects, urns
- Search Dao depends on Documents
Additionally, there are some implicit concepts that require additional caveats / logic:
- Browse Paths - Requires defining logic in an entity-specific index builder to generate.
- Urns - Requires defining a) an Urn PDL model and b) a hand-written Urn class
As you can see, there are many tied up concepts. Fundamentally changing the model would require a serious amount of refactoring, as it would require new versions of numerous components.
The challenge is, how can we meet the requirements without fundamentally altering the model?
Proposed Solution
In a nutshell, the idea is to consolidate the number of models + code we need to write on a per-entity basis. We intend to achieve this by making search index + relationship configuration declarative, specified as part of the model definition itself.
We will use this configuration to drive more generic versions of the index builders + rest resources, with the intention of reducing the overall surface area of GMS.
During this initiative, we will also seek to make the concepts of Browse Paths and Urns declarative. Browse Paths will be provided using a special BrowsePaths aspect. Urns will no longer be strongly typed.
To achieve this, we will attempt to generify many components throughout the stack. Currently, many of them are defined on a per-entity basis, including
- Rest.li Resources
- Index Builders
- Graph Builders
- Local, Search, Browse, Graph DAOs
- Clients
- Browse Path Logic
along with simplifying the number of raw data models that need defined, including
- Rest.li Resource Models
- Search Document Models
- Relationship Models
- Urns + their java classes
From an architectural PoV, we will move from a before that looks something like this:
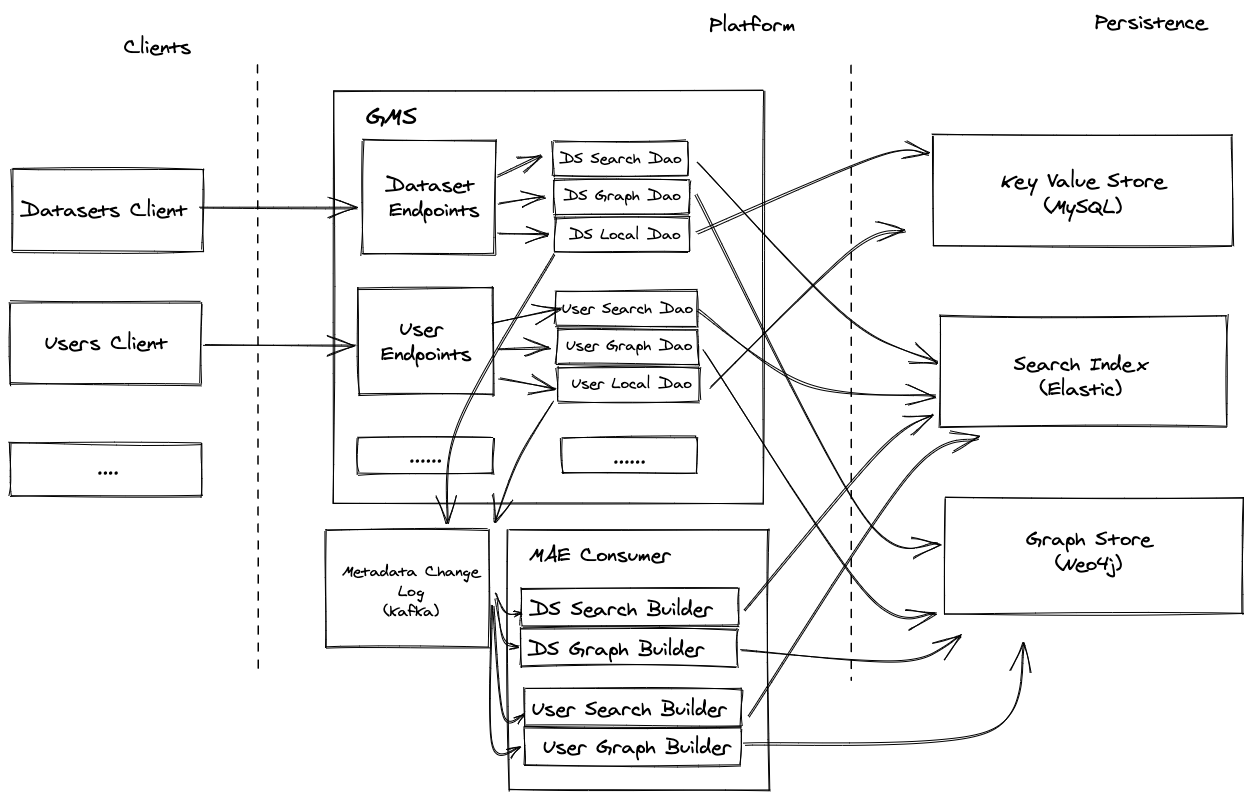
to an after that looks like this
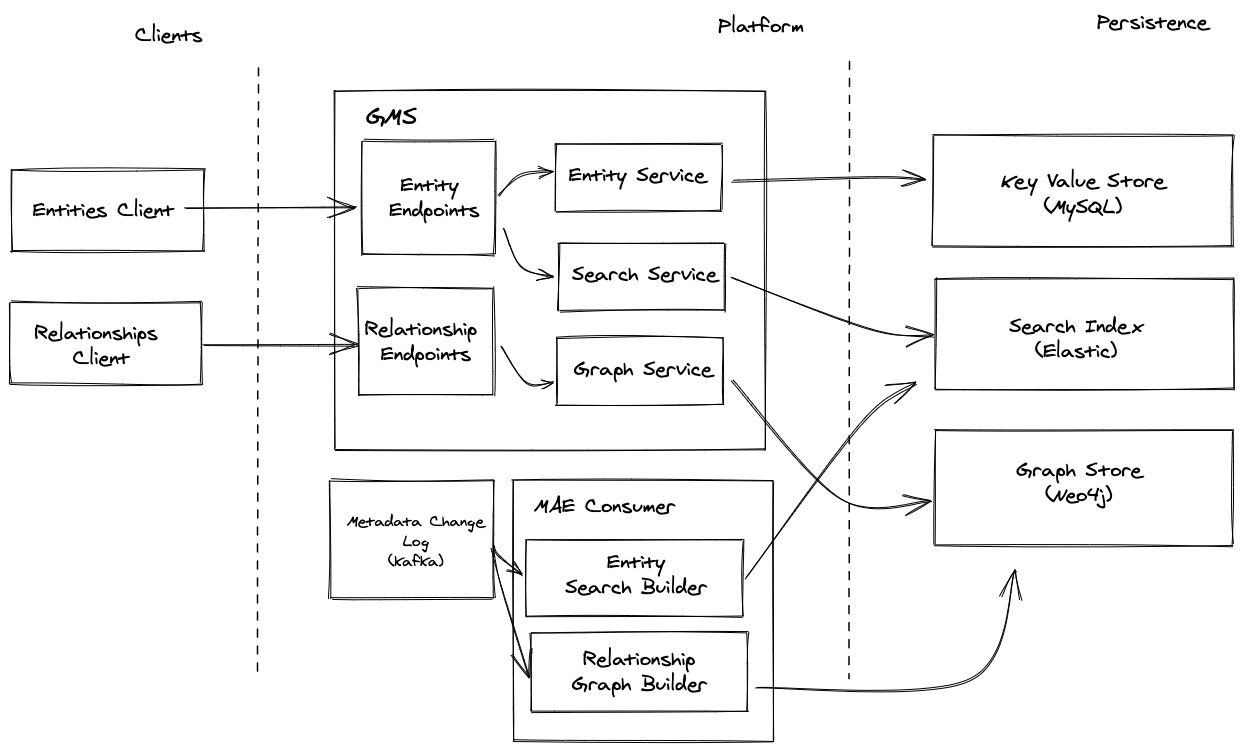
That is, a move away from patterns of strong-typing-everywhere to a more generic + flexible world.
How will we do it?
We will accomplish this by building the following:
- Set of custom annotations to permit declarative entity, search, graph configurations
- @Entity & @Aspect
- @Searchable
- @Relationship
- Entity Registry: In-memory structures for representing, storing & serving metadata associated with a particular Entity, including search and relationship configurations.
- Generic Entity, Search, Graph Service classes: Replaces traditional strongly-typed DAOs with flexible, pluggable APIs that can be used for CRUD, search, and graph across all entities.
- Generic Rest.li Resources:
- 1 permitting reading, writing, searching, autocompleting, and browsing arbitrary entities
- 1 permitting reading of arbitrary entity-entity relationship edges
- Generic Search Index Builder: Given a MAE and a specification of the Search Configuration for an entity, updates the search index.
- Generic Graph Index Builder: Given a MAE and a specification of the Relationship Configuration for an entity, updates the graph index.
- Generic Index + Mappings Builder: Dynamically generates index mappings and creates indices on the fly.
- Introduce of special aspects to address other imperative code requirements
- BrowsePaths Aspect: Include an aspect to permit customization of the indexed browse paths.
- Key aspects: Include "virtual" aspects for representing the fields that uniquely identify an Entity for easy reading by clients of DataHub.
Final Developer Experience: Defining an Entity
We will outline what the experience of adding a new Entity should look like. We will imagine we want to define a "Service" entity representing online microservices.
Step 1. Add aspects
ServiceKey.pdl
namespace com.linkedin.metadata.key
/**
* Key for a Service
*/
@Aspect = {
"name": "serviceKey"
}
record ServiceKey {
/**
* Name of the service
*/
@Searchable = {
"fieldType": "TEXT_PARTIAL",
"enableAutocomplete": true
}
name: string
}
ServiceInfo.pdl
namespace com.linkedin.service
import com.linkedin.common.Urn
/**
* Properties associated with a Tag
*/
@Aspect = {
"name": "serviceInfo"
}
record ServiceInfo {
/**
* Description of the service
*/
@Searchable = {}
description: string
/**
* The owners of the
*/
@Relationship = {
"name": "OwnedBy",
"entityTypes": ["corpUser"]
}
owner: Urn
}
Step 2. Add aspect union.
ServiceAspect.pdl
namespace com.linkedin.metadata.aspect
import com.linkedin.metadata.key.ServiceKey
import com.linkedin.service.ServiceInfo
import com.linkedin.common.BrowsePaths
/**
* Service Info
*/
typeref ServiceAspect = union[
ServiceKey,
ServiceInfo,
BrowsePaths
]
Step 3. Add Snapshot model.
ServiceSnapshot.pdl
namespace com.linkedin.metadata.snapshot
import com.linkedin.common.Urn
import com.linkedin.metadata.aspect.ServiceAspect
@Entity = {
"name": "service",
"keyAspect": "serviceKey"
}
record ServiceSnapshot {
/**
* Urn for the service
*/
urn: Urn
/**
* The list of service aspects
*/
aspects: array[ServiceAspect]
}
Step 4. Update Snapshot union.
Snapshot.pdl
namespace com.linkedin.metadata.snapshot
/**
* A union of all supported metadata snapshot types.
*/
typeref Snapshot = union[
...
ServiceSnapshot
]
Interacting with New Entity
- Write Entity
curl 'http://localhost:8080/entities?action=ingest' -X POST -H 'X-RestLi-Protocol-Version:2.0.0' --data '{
"entity":{
"value":{
"com.linkedin.metadata.snapshot.ServiceSnapshot":{
"urn": "urn:li:service:mydemoservice",
"aspects":[
{
"com.linkedin.service.ServiceInfo":{
"description":"My demo service",
"owner": "urn:li:corpuser:user1"
}
},
{
"com.linkedin.common.BrowsePaths":{
"paths":[
"/my/custom/browse/path1",
"/my/custom/browse/path2"
]
}
}
]
}
}
}
}'
- Read Entity
curl 'http://localhost:8080/entities/urn%3Ali%3Aservice%3Amydemoservice' -H 'X-RestLi-Protocol-Version:2.0.0'
- Search Entity
curl --location --request POST 'http://localhost:8080/entities?action=search' \
--header 'X-RestLi-Protocol-Version: 2.0.0' \
--header 'Content-Type: application/json' \
--data-raw '{
"input": "My demo",
"entity": "service",
"start": 0,
"count": 10
}'
- Autocomplete
curl --location --request POST 'http://localhost:8080/entities?action=autocomplete' \
--header 'X-RestLi-Protocol-Version: 2.0.0' \
--header 'Content-Type: application/json' \
--data-raw '{
"query": "mydem",
"entity": "service",
"limit": 10
}'
- Browse
curl --location --request POST 'http://localhost:8080/entities?action=browse' \
--header 'X-RestLi-Protocol-Version: 2.0.0' \
--header 'Content-Type: application/json' \
--data-raw '{
"path": "/my/custom/browse",
"entity": "service",
"start": 0,
"limit": 10
}'
- Relationships
curl --location --request GET 'http://localhost:8080/relationships?direction=INCOMING&urn=urn%3Ali%3Acorpuser%3Auser1&types=OwnedBy' \
--header 'X-RestLi-Protocol-Version: 2.0.0'